
Dziś omówię często niedoceniany temat w procesie budowy modelu uczenia maszynowego, jakim jest zaawansowana inżynieria cech (feature engineering).
Na pewno wielu z nas słyszało o tym pojęciu. Jest ono zwykle omawiane podczas studiów lub popularnych kursów. Jednak z mojego doświadczenia wynika, że kiedy tworzymy praktyczne projekty ML, to często nie poświęcamy należytej uwagi odpowiedniemu przygotowaniu cech dla modelu. Jakoś chętniej eksperymentujemy z hiperparametrami, czy próbujemy użycia różnich architektur, niż wypracowania wysokiej jakości cech.
Tymczasem często to właśnie inteligentny, przemyślany dobór cech pozwala na osiągnięcie wysokiej skuteczności modeli i decyduje o sukcesie lub porażce całego projektu.
Dlatego w tym wpisie przedstawię Ci klasyfikację metod inżynierii cech, jaką wyprowadziłem z obserwacji różnych projektów. I teraz w zależności od zadania, które realizujesz, zachęcam Cię do użycia części lub wszystkich metod inżynierii cech, aby zmaksymalizować potencjał w danych i wytrenować jak najlepszy model.
Ograniczę się tutaj głównie do tzw. danych ustrukturyzowanych (tabelarycznych) – zakładam, że nasze dane są tabelce z określoną liczbą wierszy i kolumn. Efektem inżynierii cech będzie nowa tabelka – z tą samą liczbą wierszy (w których są konkretne elementy naszego zbioru), lecz potencjalnie z inną liczbą i inną zawartością kolumn.
Możemy wyróżnić trzy podstawowe operacje w inżynierii cech:
– transformacja cech, która polega na modyfikacji zawartości określonej kolumny;
– selekcja cech – jest to po prostu usunięcie niektórych, mało znaczących kolumn;
– generowanie nowych cech, czyli dodawanie kolumn na podstawie zawartości jednej lub większej liczby istniejących już kolumn.
Po co w ogóle dokonujemy inżynierii cech?
Po to, aby ułatwić modelowi zadanie predykcji. Pamiętaj, że model to po prostu funkcja, która przekształca dane wejściowe w wyjście (output). Nawet jeśli jest ona bardzo zaawansowana, to wciąż ma swoje ograniczenia, które możemy zniwelować poprzez odpowiednią modyfikację danych wejściowych.
Transformacja cech
W tym podejściu przekształcamy określoną cechę (kolumnę) danych na nową kolumnę lub na większą liczbę kolumn. Wyróżniamy tutaj kilka możliwości.
Skalowanie zmiennych
Standaryzacja
Za tę operację odpowiada StandardScaler z biblioteki Scikit learn . Przekształca ona cechy tak, aby miały średnią 0 oraz wariancję równą 1. Jest ona konieczna w przypadku niektórych modeli (regresje, SVM, sieci neuronowe), a pomocna bywa prawie zawsze, gdyż niweluje różnicę skali w różnych cechach i sprawia, że model traktuje cechy tak samo, nie sugerując się ich skalą.
Pamiętaj jednak, że standaryzacja ma sens przy rozkładach cech zbliżonych do rozkładu normalnego. Jeśli Twój rozkład jest typu fat tails, tzn. występuje dużo skrajnych wartości, które zaburzają średnią lub wariancję, standaryzacja może nie mieć sensu. Podobnie, jeśli nie usuniemy ze zbioru outlierów.
Normalizacja
Jest to liniowe przekształcenie naszej cechy do określonego przedziału, np. [0, 1]. Odpowiada za to funkcja MinMaxScaler. Jest to dobre podejście, gdy chcemy mieć pewność, że cechy znajdują się w określonym przedziale (bo np. nasz model nie radzi sobie z wartościami ujemnymi lub większymi niż 1). Podobnie jak wcześniej, outliery mogą znacznie zaburzyć to przekształcenie.
Kodowanie kategorii
Ta transformacja jest konieczna, jeśli w tabelce posiadasz zmienne tzw. kategoryczne (np. zawód, miasto, produkt), a Twój model potrzebuje danych liczbowych (na przykład klasyczna sieć neuronowa). Zakodowanie kategorii jako liczb możemy wykonać na kilka sposobów:
- One-hot encoding – tworzymy kolumny dla każdej kategorii, wypełnione wartościami 0 i 1, wskazujące obecność danej kategorii w oryginalnej kolumnie. Jeśli przykładowo mamy 5 możliwych wartości w kolumnie “zawód”, to zamieniamy ją na 5 nowych kolumn.
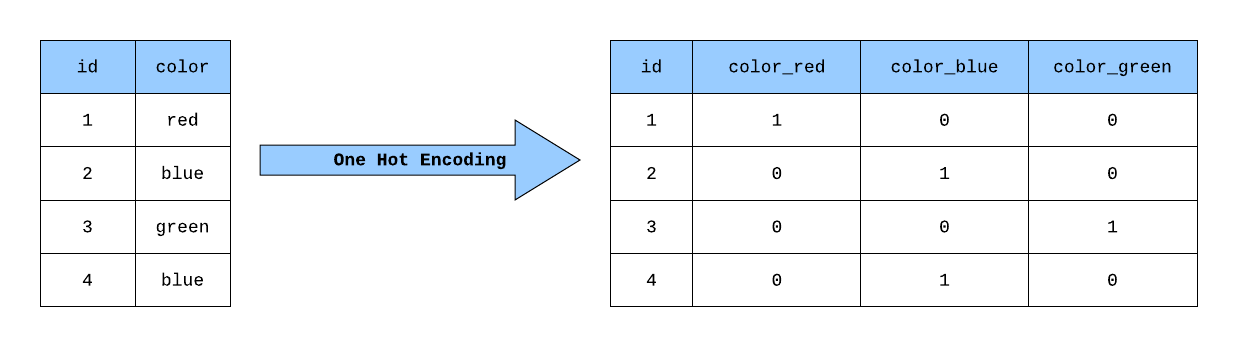
- Kodowanie częstościowe – każda kategoria otrzymuje jedną liczbę, która koduje informację, na ile zmienna jest istotna w odniesieniu do wartości, którą chcemy przewidywać. W ten sposób działa kodowanie w algorytmie CatBoost.
- Embeddingi – używane szczególnie przy dużej liczbie kategorii. Zamiast wektorów o długości równej liczbie kategorii (jak w one-hot encoding), tworzymy wektory o mniejszej długości, które kodują bardziej skomplikowane relacje między kategoriami. W ten sposób możemy kodować nie tylko kategorie, ale również dane nieustrukturyzowane, jak teksty czy grafiki.

Selekcja cech
Selekcja cech jest istotna, kiedy masz zbyt wiele cech, co może powodować, że algorytm gubi się w zbiorze danych (przyjmuje się zwykle, że wierszy powinno być co najmniej kilkadziesiąt razy więcej niż kolumn). Można ją wykonać na kilka sposobów:
- Analiza wariancji – obliczamy wariancję każdej kolumny i wybieramy te o najwyższej wariancji, ponieważ zazwyczaj są one ważniejsze (niosą w sobie więcej informacji).
- Analiza korelacji – sprawdzamy korelacje pomiędzy cechami a targetem oraz pomiędzy cechami nawzajem. Usuwamy cechy o niskiej korelacji z targetem oraz te, które są wysoko skorelowane ze sobą.
- Zaawansowane algorytmy, np. algorytm Boruta, który wykorzystuje las losowy do oceny istotności cech, eliminując te, które nie są bardziej istotne od losowych cech.
Generowanie nowych cech
Generowanie nowych cech często decyduje o sukcesie modelu, ponieważ umożliwia wychwycenie zależności, których nie obsługuje dany model (przykładowo – regresja liniowa nie obsługuje iloczynów między cechami). W tym aspekcje często pomaga kontakt z ekspertami dziedzinowymi, którzy mają wiedzę lub intuicję, jakie cechy mogą być istotne. Można wyróżnić kilka grup nowych cech.
Agregaty cech
Agregujemy jedną kolumnę za pomocą jakiejś operacji grupowej, np. suma, średnia, czy maksymalna wartość (tutaj lista gotowych funkcji agregujących zaimplementowanych w bibliotece Pandas).
Cechy relacyjne
Bazują na relacjach matematycznych między dwiema lub więcej cechami. Najprostsze przykłady to ilorazy (stosunki) dwóch zmiennych. Jeśli przykładowo mamy informacje o PKB danego kraju oraz o liczbie mieszkańców, możemy stworzyć nową cechę – PKB na miekszańca.
Warto zauważyć, że taka operacja może być kluczowa na przykład dla algorytmów predykcyjnych opartych o drzewa decyzyjne, które – jeśli nie dostaną wprost ilorazu dwóch kolumn – będą próbowały nauczyć się tej zależności przez tworzenie bardzo wielu węzłów w drzewie.
Zmienne czasowe
Możliwe do stworzenia tam, gdzie dane mają aspekt czasu. Wówczas tworzymy nową cechę, która uwzględnia ten aspekt czasowy. Jeśli mamy informacje o filmach ocenianych przez użytkowników, to nową cechą może być przykładowo liczba ocenionych filmów przez danego użytkownika w ostatnim tygodniu. Mamy tutaj możliwość zastosowania zarówno różnych przedziałów czasu (np. ostatni dzień, tydzień, 2 tygodnie, miesiąc itd.), jak i funkcji agregujących (suma, maksimum itd.).
Cechy łączone
Jest to połączenie cech relacyjnych, agregatów i zmiennych czasowych. Przykładem takiej zaawansowanej cechy może być średnia liczba wyświetleń danej kategorii filmów przez użytkownika w danym miesiącu, podzielona przez średnią liczbę wyświetleń tej kategorii przez wszystkich użytkowników.
Warto zaważyć, że tymi operacjami możemy zwiększyć liczbę cech nawet kilkudziesięciokrotnie. Wówczas konieczna może się okazać ponowna selekcja cech. Pamiętaj, że praca z danymi to podejście iteracyjne – analogicznie jak budowa modelu. Dlatego często stosujemy podejścia z różnych kategorii (transformacja – generowanie – selekcja cech) naprzemiennie, aż do uzyskania najlepszego wyniku modelu.
Warto podejście związane z inżynierią cech połączyć z analizą istotności cech (np. przez parametry typu feature_importance w lasach losowych, czy przez dodatkowe algorytmy, jak SHAP). Wówczas jeśli widzimy, że nowa cecha ma dużą wartość, warto wejść głębiej i wygenerować jej różne warianty, by jeszcze bardziej ułatwić zadanie modelowi.
Podsumowanie
Zaawansowana inżynieria cech jest kluczowym elementem w procesie budowy skutecznych modeli uczenia maszynowego. Pozwala na maksymalizację potencjału danych i znacząco wpływa na wyniki predykcji. Jest to element tzw. Data Centric Approach, w którym główną uwagę w projekcie przykładamy do poprawiania danych, a nie do testowania różnych modeli i ich hiperparametrów.
Jeśli ten wpis dał Ci wartość, podziel się koniecznie ze mną w komentarzu Twoją opinią!



