
W tym wpisie przedstawiam analizę określenia “sztuczna inteligencja”. Podam argumenty za tym, że nie jest to poprawne ani właściwe określenie. Zaproponuję alternatywne określenia i wyjaśnię, dlaczego są lepsze. Przy okazji podam moje stanowisko dotyczące często pojawiających się wątpliwości, takich jak czy algorytmy mogą mieć świadomość lub rozumienie.
Wstęp
Określenie “sztuczna inteligencja” (ang. artificial intelligence) pojawiło się w kontekście naukowym w latach 50. XX wieku. Jednak dopiero wraz z pojawieniem się narzędzia ChatGPT weszło do codziennego języka. Wraz z nim pojawiają się pytania dotyczące jego istoty, potencjału oraz zagrożeń.
Mimo że sam w komunikacji codziennej posługuję się tym sformułowaniem, uważam je za wewnętrznie sprzeczne oraz wprowadzające w błąd. Posługuję się nim z uwagi na brak alternatywnego, powszechnie uznanego określenia.
Ten artykuł wynika z mojej potrzeby wyjaśnienia mojego stanowiska, w kontekście posługiwania się przeze mnie tym określeniem w różnych sytuacjach.
Analiza etymologiczna
W sformułowaniu “sztuczna inteligencja” pierwszy człon raczej nie budzi wątpliwości.
“Sztuczny” jest efektem “sztuki”, działania człowieka. Słownik języka polskiego podaje wyjaśnienie przymiotnika “sztuczny” jako “stworzony przez człowieka w celu zastąpienia naturalnego odpowiednika”, co faktycznie odzwierciedla intencję tworzenia algorytmów AI.
Z kolei angielskie artificial, pochodzi z łacińskiego artificialis, a to od artifex – ten, kto uprawia jakąś sztukę, od “ars” (sztuka) + “facere” (robić, czynić). Zatem jest to podobne znaczeniowo do “sztuczny” i również jest jednoznaczne i odpowiednie.
Skupmy się na słowie “inteligencja”. Jest to kalka również z łacińskiego intelligentia, czyli rzeczownika pochodzącego od czasownika intelligere, oznaczającego rozumieć, pojmować (ale też “spostrzegać, zauważyć, poznać, widzieć oraz mniemać, sądzić, wyobrażać sobie”). Intelligere pochodzi od inter (między) + legere (zbierać, gromadzić ale też czytać). Określano tym czasownikiem zatem nie tylko proces zdobywania informacji, ale selekcjonowania ich i odróżniania tego, co prawdziwe od tego, co tylko pozorne.
Samo łacińskie intelligentia tłumaczy się jako “zdolność pojmowania, rozum”, alternatywne znaczenia to “zrozumienie, znajomość, znawstwo” oraz “pojęcie, wyobrażenie” (Słownik łacińsko-polski, Kazimierz Kumaniecki)
Czyli inteligencja przede wszystkim to zdolność pojmowania i rozumienia (wg SJP «zdolność rozumienia, uczenia się oraz wykorzystywania posiadanej wiedzy i umiejętności w sytuacjach nowych» https://sjp.pwn.pl/szukaj/inteligencja.html).
I tutaj pojawia się główny problem.
Tworząc algorytmy AI oczekujemy, że będą w jakiś sposób imitowały zachowania człowieka. Że będą w stanie wykonywać skomplikowane operacje. Ale chyba na ostatnim miejscu oczekujemy, że one faktycznie “rozumieją”.
Pojawia się też pytanie:
Co to znaczy “pojmować” / “rozumieć”?
To pytanie jest ściśle filozoficzne. Różne szkoły i poglądy dają różne odpowiedzi.
W uproszczeniu mamy poglądy materialistyczne, które twierdzą, że istnieje tylko świat materialny, w którym człowiek jest bardzo zaawansowaną, ale jednak jedynie “maszyną biologiczną”. Wówczas “rozumienie” definiuje się często poprzez zachowanie. Przykładowo, uznaję, że człowiek rozumie moje słowa, jeśli na przykład poproszę o zakup jakiegoś przedmiotu i on faktycznie go kupi. Nie rozważamy tutaj zupełnie stanów wewnętrznych tej osoby i jak ona interpretuje polecenia. Liczy się efekt, czyli funkcja, którą dana osoba spełnia.
Innym stanowiskiem jest emergentyzm, który uważa, że istnieje pewna “część” niematerialna (odpowiadająca na przykład za świadomość), która wyłania się sama w dostatecznie skomplikowanych systemach.
I wreszcie mamy stanowiska, które możemy określić jako dualistyczne, postulujące istnienie w człowieku oddzielnego elementu niematerialnego, który odpowiada za poznawanie oraz takie elementy, jak wolna wola.
Nie chcę teraz argumentować za którymś z tych stanowisk. Natomiast zauważmy, że przyjęcie koncepcji, że człowiek tworzy faktyczną “sztuczną inteligencję” (czyli algorytmy, które osiągają poziom rozumienia podobny do człowieka) zakłada przyjęcie któregoś z dwóch pierwszych stanowisk.
Jest to ważne spostrzeżenie, ponieważ ukazuje, że trafność pojęcia “sztuczna inteligencja” w dużej mierze zależy od przyjętej filozofii.
W koncepcji dualistycznej, którą ja przyjmuję, kwestia “rozumienia” jest ściśle związana właśnie z naszą częścią niematerialną, której nie wytwarzamy w procesie budowy algorytmów, a która odpowiada za poznawanie obiektywnie istniejącej prawdy. W takiej koncepcji określenie “sztuczna inteligencja” jest sprzecznością.
W dalszej części przedstawiam inne argumenty za nietrafnością sformułowania “sztuczna inteligencja”.
Problem z “testami na inteligencję”
Słowo “inteligencja” pojawia się również w tzw. “testach na inteligencję”.
Można argumentować, że skoro algorytmy radzą sobie lepiej w tych testach niż ludzie, to czy to nie oznacza, że są naprawdę inteligentne?
Tylko czy w “testach na inteligencje” faktycznie chodzi o mierzenie inteligencji w tym podstawowym znaczeniu, jako zdolność pojmowania / rozumienia? Myślę, że bardziej chodzi w nich o takie czynniki jak spostrzegawczość, bystrość, czy po prostu umiejętność znajdowania analogii.
Wiemy, że już teraz algorytmy osiągają wysokie wyniki w testach IQ. Jest bardzo prawdopodobne, że wkrótce będą lepsze w tych testach od najbardziej inteligentnych ludzi. Tylko to nie oznacza w żaden sposób, że rozumieją to, co generują.
Stanowisko Rogera Penrose’a
Roger Penrose uważa, że sztuczna inteligencja nie istnieje, ponieważ istniejące algorytmy nie mają zdolności odróżniania twierdzeń prawdziwych od fałszywych.
Wyprowadza to z twierdzenia Gödla, które mówi, że w każdym wystarczająco skomplikowanym systemie matematycznym zawsze będą istniały zdania, które są prawdziwe, ale których nie da się udowodnić w tym systemie.
Penrose tłumaczy, że systemy zbudowane na obecnych komputerach są ograniczone przez ich operacje, a więc one są na poziomie jak gdyby dowodzenia pewnych twierdzeń, natomiast nie mają możliwości sprawdzania, czy faktycznie określone twierdzenia są prawdziwe (te, które nie mają dowodu w tym systemie).
Penrose nie wyklucza możliwości powstania prawdziwej sztucznej inteligencji w przyszłości, jednak jej działanie musiałoby być na poziomie kwantowym, a nie zwykłych obliczeń, jak obecnie.
Problemy praktyczne z określeniem “sztuczna inteligencja”
Nieadekwatność pojęcia “sztuczna inteligencja” ilustrują również przykłady użycia w różnych profesjonalnych kontekstach, to znaczy w sytuacjach, z którymi mierzą się twórcy takich systemów.
Wprowadza w błąd co do użycia algorytmów
Skoro “inteligencja” w powszechnym języku oznacza “rozumienie”, osoby nieświadome tego, jak te algorytmy działają, często oczekują faktycznie głębokiego zrozumienia ze strony algorytmów. Co więcej, naturalne wydaje się im oczekiwanie, że gdy algorytm “zrozumie”, o co nam chodzi, będzie w stanie podawać poprawne odpowiedzi.
Możemy też słusznie oczekiwać, że model będzie dopytywał, dopóki nie osiągnie zrozumienia. Ponieważ tak działa nasze poznanie – dopóki widzimy, że czegoś nie rozumiemy, szukamy wyjaśnienia, dopytujemy.
Dlatego często może nas zaskakiwać fakt, że model zawsze wygeneruje jakąś odpowiedź. Trudno go “zmusić” do zadawania pytań. A nawet jeśli to nam się uda, to zauważymy, że model “nie wie, czego nie wie”. Model nie potrafi zrozumieć, że czegoś nie ma w danych.
Wprowadza w błąd co do klas algorytmów
Sformułowanie “sztuczna inteligencja” jest na tyle nieprecyzyjne, że kiedy rozmawiam z klientem i pojawia się to sformułowanie z jego ust, to znak, że klient jest na bardzo podstawowym poziomie rozumienia technologii. Prawdopodobnie sam nie wie, jak mógłby użyć tych algorytmów i przyszedł tylko zachęcony marketingowymi hasłami.
Z bardziej świadomymi klientami rozmawiam z użyciem wyrażeń typu modele językowe, algorytmy predykcyjne, przetwarzanie obrazu, klasyfikacja.
O ile w przypadku czatbotów LLM-ów może pojawiać się wrażenie “rozumienia”, to czy możemy tak powiedzieć na przykład o algorytmach klasyfikujących obrazy? Albo o systemie przewidującym wielkość sprzedaży? Czy ostatecznie regresja liniowa też posiada “rozumienie” danych?
Uważam, że używanie wyrażenia “sztuczna inteligencja” jest głównym powodem tego, że większość osób myśli o sztucznej inteligencji jedynie jako o systemach, które można “promptować”, które zrozumieją polecenie wydawane w języku naturalnym. I dlatego wszyscy chcą budować czatboty, a tak trudno rozmawia się o innych klasach algorytmów.
Wprowadza w błąd co do sposobu tworzenia takich algorytmów
Jeśli chcemy stworzyć “sztuczną inteligencję”, to co potrzebujemy zrobić? Trzeba w jakiś sposób zakodować “rozumienie” do algorytmu.
Tylko że w praktyce twórcy algorytmów zupełnie nie myślą o zakodowaniu “zrozumienia”, a jedynie o dostosowaniu algorytmu do posiadanych danych, wykrycia istniejących w nich zależności i uogólnienia ich.
Ktoś powie, że nie wszystkie algorytmy AI wymagają nakarmienia danymi (na przykład algorytmy optymalizacyjne czy uczenie ze wzmocnieniem). Jednak wówczas również definiuje się określoną funkcję, która poprzez interakcje osiąga jakiś stan optimum.
Nigdzie na tym poziomie nie ma intencji ani żadnego planu na zakodowanie “rozumienia” do algorytmu. Chodzi jedynie o uzyskanie efektu zgodnego z oczekiwaniami.
Rodzi błędne pytania i budzi niesłuszne obawy
Jeśli mamy do czynienia z systemem, który “poznaje” i “rozumie”, to oczekujemy, że ma lub przynajmniej może mieć świadomość.
Oczywiście znów wracamy do kwestii filozoficznych, czym jest świadomość. W powszechnym rozumieniu jest to “zdolność do poznawania i rozumienia siebie”, zatem “poznawanie”, “rozumienie” i “świadomość” to określenia z tej samej kategorii.
Jeśli potrafimy stworzyć sztuczne “rozumienie”, to dlaczego nie mielibyśmy możliwości stworzyć sztucznej “świadomości” i dalej “sztucznej wolnej woli”?
Rozumując w ten sposób, dochodzimy do pytań dotyczących podmiotowości takich bytów. Czy jeśli nas przewyższą, to czy nie powinniśmy im oddać możliwości decydowania o ważnych sprawach? Głosowania w wyborach? Sprawowania władzy?
A czy zadalibyśmy takie same pytania co do zaawansowanego kalkulatora?
Powoduje personalizację techniki i depersonalizację człowieka
Konsekwentne używanie określenia “sztuczna inteligencja” będzie powodowało coraz mniejsze uznanie człowieka za istotę wyjątkową (pisałem o tym tutaj ).
Tak jak pisałem wcześniej, wynika ono zwykle z materialistycznego traktowania człowieka i powoduje nieświadome utrwalanie się tej filozofii.
Utrata poczucia wyjątkowości człowieka będzie prowadzić do pogłębienia poczucia bezsilności, bycia niepotrzebnym, wyeliminowanym. Dlatego tak popularne teraz są pytania o to, czy sztuczna inteligencja nie “wyeliminuje” człowieka.
Propozycja nowego określenia
Poszukując odpowiedniego określenia dla tej klasy algorytmów, wyszedłem od przyjętego powszechnie określenia “modele językowe”, które oznacza pewną klasę algorytmów przetwarzających tekst.
Samo słowo “model” ma w SJP wiele znaczeń, chyba najbardziej odpowiednie w tym kontekście są dwa:
«konstrukcja, schemat lub opis ukazujący działanie, budowę, cechy, zależności jakiegoś zjawiska lub obiektu»
«przedmiot będący kopią czegoś, wykonany zwykle w mniejszych rozmiarach»
Co do “modelu”, nie mamy wątpliwości, że jest to tylko niedoskonała kopia. Zachowuje pewną “formę”, ale brakuje jej istoty oryginału.
Możemy modelować nie tylko język, ale też obrazy, dźwięk, wideo i inne typy danych. Dlatego określenie “modelowanie” jest bardzo ogólne i naturalne. Potrzebujemy tylko dopełnienia – uniwersalnego wyrazu, który będzie odpowiedni dla różnych typów modeli.
Proponuję tutaj trzy opcje: modelowanie informacji, modelowanie danych lub – jeśli zależy nam na zachowaniu słowa “inteligencja” – modelowanie inteligencji. Określenie “modelowanie inteligencji” jest lepsze niż “sztuczna inteligencja”, ponieważ ukazuje, że nie próbujemy stworzyć inteligencję, a jedynie zamodelować istniejące zjawisko. Z wymienionych trzech propozycji, najlepsze jednak wydaje mi się określenie “modelowanie informacji”.
Przewagi określenia “modelowanie informacji”
Ukazanie związku z danymi
Jeśli tworzymy algorytmy modelujące informacje, od razu jasne jest, że potrzebujemy wejścia w postaci informacji, które mają być przetworzone.
Naturalne uogólnienie istniejących określeń
Modele informacji w sposób naturalny mają podział na modele językowe, modele obrazu, modele wideo itp. (czego nie można powiedzieć o “sztucznej inteligencji”).
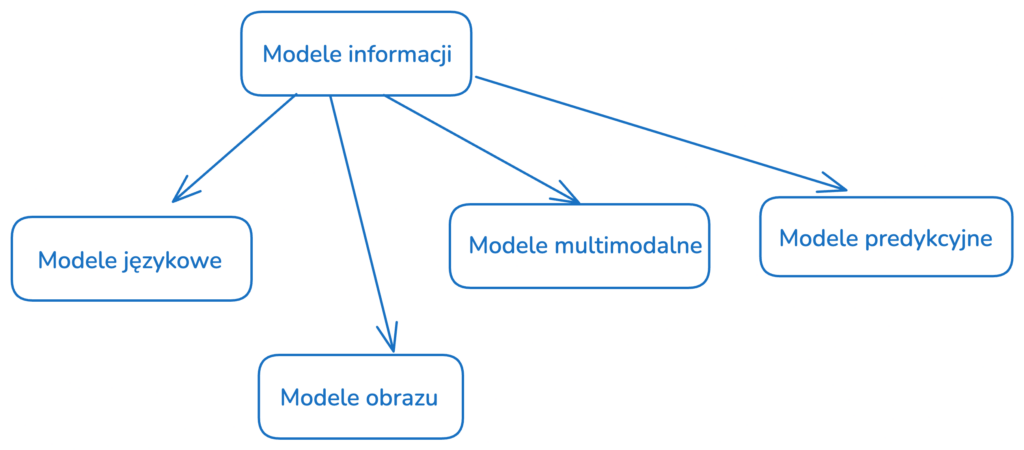
Nie sugeruje podmiotowości algorytmów
“Modelowanie” z definicji jest niedoskonałą kopią czegoś istniejącego i nie rodzi pytań o możliwość świadomości, czy wolnej woli.
Co z AGI i superinteligencją?
Algorytmy mogą osiągnąć bardzo zaawansowany poziom przeprowadzania rozumowania, znacznie przewyższający człowieka.
Nie powinno nas to zaskakiwać, skoro nie potrafimy przeprowadzić w pamięci mnożenia przez siebie kilkucyfrowych liczb, a najprostszy kalkulator robi to z łatwością.
Przełomem będzie prawdopodobnie poziom zaawansowania wykonywanych zadań i łatwość komunikacji w języku naturalnym.
Do tej pory komputery dobrze sobie radziły w przypadku precyzyjnie zdefiniowanych reguł (takich jak na przykład gra w szachy, czy wykonywanie obliczeń matematycznych). Jednak istnieje wiele obszarów życia, wymagających zaawansowanego rozumowania (jak na przykład badania naukowe lub zarządzanie firmą), gdzie tych reguł nie da się w prosty sposób określić.
Ponadto tak naprawdę od początku celem informatyki była budowa komputera, z którym można się komunikować całkowicie swobodnie.
Powolny rozwój technologii sprawił, że powstawały dość prymitywne języki programowania, które jednak próbowały z czasem naśladować jak najbardziej naturalną składnię (np. SQL).
Jestem w stanie wyobrazić sobie przyszłość, gdzie przeprowadzanie jakiegokolwiek większego rozumowania w niemal dowolnej dziedzinie nie będzie miało sensu bez wcześniejszego zapytania algorytmu o jego rekomendacje (właściwie już teraz podejmowanie decyzji, na przykład w biznesie, bez opierania się o zewnętrzne narzędzia, typu Excel, prowadzi do nieporównywalnie słabszych wyników).
Ktoś może powiedzieć, że to już będzie AGI lub superinteligencja.
Natomiast uważam, że wciąż to będzie “super-rozumowanie”, a nie “super-rozumienie”. To, że algorytmy będą w stanie przeprowadzać podobne kroki myślowe do ludzi (i to znacznie sprawniej), to nie oznacza, że będą mieć poznanie i zrozumienie rzeczywistości. Nie będą zatem miały żadnej podmiotowości ani żadnej możliwości zyskania świadomości.
Podsumowanie
W tym wpisie przedstawiłem analizę językową określenia “sztuczna inteligencja” i ukazałem na jego nieadekwatność, skutkującą wieloma praktycznymi problemami.
Uważam, że język ma możliwość kształtowania poglądów i w tym przypadku bliskie jest mi spojrzenie neopozytywistów, którzy uważali, że wiele odwiecznych pytań ludzkości to są po prostu błędnie sformułowane “pseudozagadnienia”. Uważam, że taka sytuacja ma miejsce właśnie w przypadku określenia “sztuczna inteligencja”, które – z powodu błędu, który zawiera – rodzi również niesłuszne pytania i obawy takie jak “czy sztuczna inteligencja może mieć świadomość” (zakładające poznanie) lub “co się stanie, jeśli sztuczna inteligencja się zbuntuje” (zakładające wolną wolę).
Postuluję próbę stosowania alternatywnych określeń i rozpoczęcie debaty w tym temacie.

